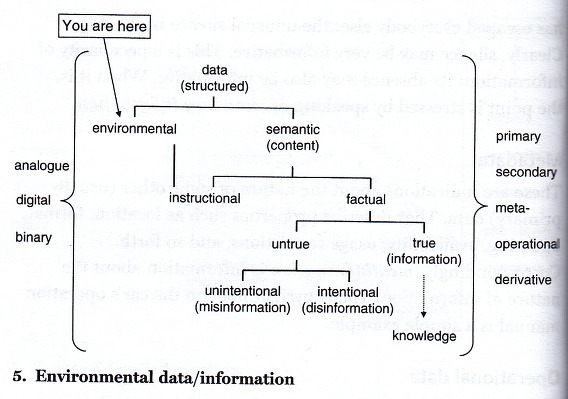
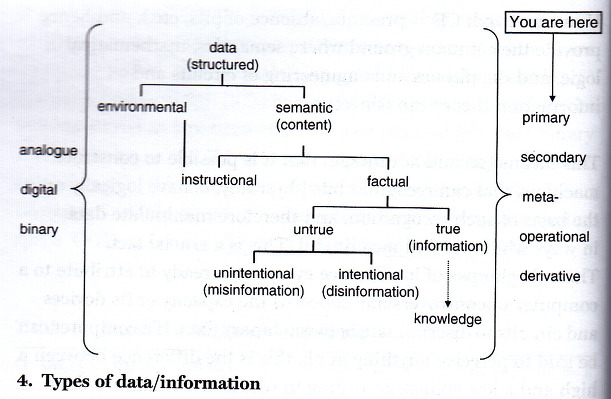
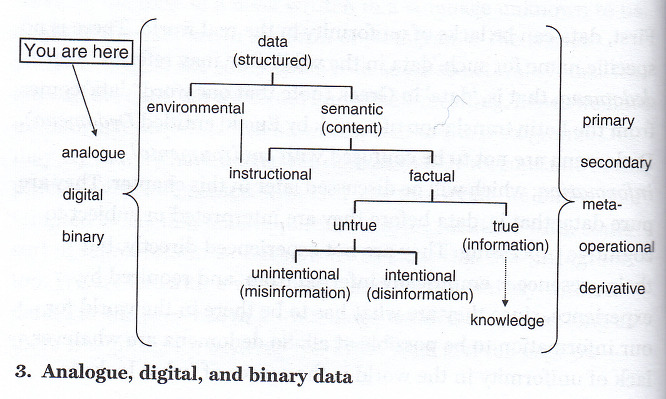
정보에 대한 정의
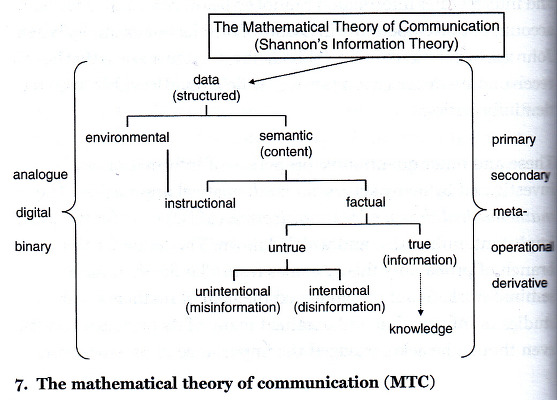
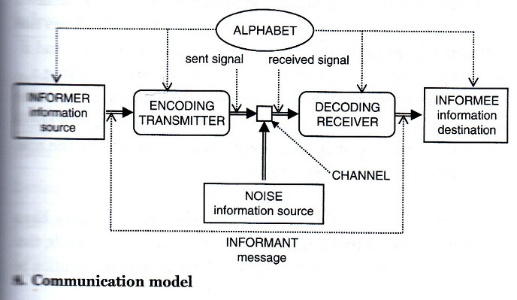
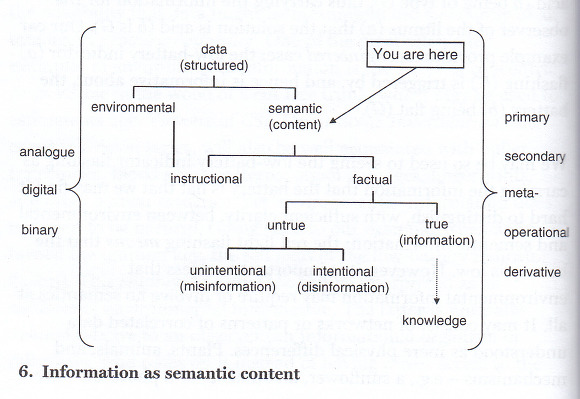
정보는 데이터들의 결합과 분석으로 만들어진다. 정보는 어떤 사물이나 사태에 대한 정황을 반영하고 있다. 미국의 수학자이자 공학자인 클로드 섀넌(Claude Shannon)은 '커뮤니케이션의 수학적 이론(A Mathematical Theory of Communication)'에서 "정보란 잡음(noise)이 배제된 메시지 신호(signal)"로 보았다. 그는 신호의 입력이 출력되어 나오는 과정에서 잡음을 최소화하여 원래 투입한 신호가 그대로 전송되는 과정과 그에 필요한 조건을 연구하였다. 입력 신호가 잡음 없이 전달되기 위해서는 중간 전송 과정에 피드백이 필요하다. 정보에 대한 기술적 정의에서는 잡음 없는 전송 시스템을 설계하는 것이 가장 중요한 부분을 구성한다.
‘정보는 다름을 만드는 모든 차이’라 주장한 그레고리 뱃슨(Gregory Bateson, 1904~1980)
ⓒ 커뮤니케이션북스
한편 그레고리 뱃슨(Gregory Bateson)은 "다름을 만드는 모든 차이가 정보다"라고 정의했다. 이것은 정보를 잡음 없이 전달하는 섀넌의 정보공학적 전달 형식과는 달리 내용과 관련된 의미론적 규정이다. 차이를 만드는 것은 모두 정보다. 다른 사람과 차이를 드러내 보이니까 내 얼굴이나 목소리도 정보다. 이런 문화적인 차이와 사회적인 의미를 담고 있는 것이 뱃슨의 정보에 대한 정의다. 섀넌의 정보가 기술적인 정의라면 뱃슨의 이런 정의는 의미론적인 정의다.
루치아노 플로리디(Luciano Floridi)는 정보를 (1) 어떤 대상에 대한 정보(Information about something) (2) 대상으로서 정보(Information as something) (3) 대상을 위한 정보(Information for something) (4) 대상 안에 있는 정보(Information in something)로 분류하였다. 대상에 대한 정보는 기차 시간표처럼 어떤 대상에 관한 정보다. 무엇으로서의 정보는 DNA나 지문처럼 그 대상의 특성과 속성을 보여 주는 정보다. 속성 정보는 대상의 바깥이 아니라 안쪽을 펼쳐 보이는 정보로서 그 대상이 무엇인가에 관한 정보다. 그다음으로 무엇을 위한 정보, 곧 목적성 정보를 꼽을 수 있다. 컴퓨터 프로그램의 특정한 알고리즘은 이루고자 하는 목적에 도달하기 위한 최적의 지시를 담고 있다. '3시에 밥을 먹어라', '60점 이하의 점수를 받은 학생들만 골라내라' 등은 무엇을 위한 정보다. 마지막으로 대상 안에 들어 있는 정보가 있다. 무엇 안에 있는 정보는 어떠한 형태나 패턴을 말한다.
[네이버 지식백과] 정보 (디지털 데이터, 정보, 지식, 2013.02.25., 커뮤니케이션북스)
정보는 데이터들의 결합과 분석으로 만들어진다. 정보는 어떤 사물이나 사태에 대한 정황을 반영하고 있다. 미국의 수학자이자 공학자인 클로드 섀넌(Claude Shannon)은 '커뮤니케이션의 수학적 이론(A Mathematical Theory of Communication)'에서 "정보란 잡음(noise)이 배제된 메시지 신호(signal)"로 보았다. 그는 신호의 입력이 출력되어 나오는 과정에서 잡음을 최소화하여 원래 투입한 신호가 그대로 전송되는 과정과 그에 필요한 조건을 연구하였다. 입력 신호가 잡음 없이 전달되기 위해서는 중간 전송 과정에 피드백이 필요하다. 정보에 대한 기술적 정의에서는 잡음 없는 전송 시스템을 설계하는 것이 가장 중요한 부분을 구성한다.
‘정보는 다름을 만드는 모든 차이’라 주장한 그레고리 뱃슨(Gregory Bateson, 1904~1980)
ⓒ 커뮤니케이션북스
한편 그레고리 뱃슨(Gregory Bateson)은 "다름을 만드는 모든 차이가 정보다"라고 정의했다. 이것은 정보를 잡음 없이 전달하는 섀넌의 정보공학적 전달 형식과는 달리 내용과 관련된 의미론적 규정이다. 차이를 만드는 것은 모두 정보다. 다른 사람과 차이를 드러내 보이니까 내 얼굴이나 목소리도 정보다. 이런 문화적인 차이와 사회적인 의미를 담고 있는 것이 뱃슨의 정보에 대한 정의다. 섀넌의 정보가 기술적인 정의라면 뱃슨의 이런 정의는 의미론적인 정의다.
루치아노 플로리디(Luciano Floridi)는 정보를 (1) 어떤 대상에 대한 정보(Information about something) (2) 대상으로서 정보(Information as something) (3) 대상을 위한 정보(Information for something) (4) 대상 안에 있는 정보(Information in something)로 분류하였다. 대상에 대한 정보는 기차 시간표처럼 어떤 대상에 관한 정보다. 무엇으로서의 정보는 DNA나 지문처럼 그 대상의 특성과 속성을 보여 주는 정보다. 속성 정보는 대상의 바깥이 아니라 안쪽을 펼쳐 보이는 정보로서 그 대상이 무엇인가에 관한 정보다. 그다음으로 무엇을 위한 정보, 곧 목적성 정보를 꼽을 수 있다. 컴퓨터 프로그램의 특정한 알고리즘은 이루고자 하는 목적에 도달하기 위한 최적의 지시를 담고 있다. '3시에 밥을 먹어라', '60점 이하의 점수를 받은 학생들만 골라내라' 등은 무엇을 위한 정보다. 마지막으로 대상 안에 들어 있는 정보가 있다. 무엇 안에 있는 정보는 어떠한 형태나 패턴을 말한다.
[네이버 지식백과] 정보 (디지털 데이터, 정보, 지식, 2013.02.25., 커뮤니케이션북스)